



Node.js is a javascript runtime environment that helps you create high-performance apps. Because Node.js functions are non-blocking (commands execute concurrently or even in parallel, it can perform heavy tasks without incurring the cost of thread context switching. For that reason, it’s perfect to use Node.js for scraping web pages.
In this article, we will crawl and extract all links (including “href” and “text”) from a webpage using Node.js and 2 packages: got and cheerio.
- got is an easy-to-use and powerful HTTP request library for Node.js that will help download HTML from a webpage.
- cheerio is a fast implementation of core jQuery designed specifically for the server that can help us parse HTML much easier.
Table of Contents
The Example Project
In this example, we will get all links from the homepage of a website named books.toscrape.com which lets us free to scrape it without worrying about any legal issues.
1. Open your terminal and navigate to the folder you want your project lives in then run then create a new file named index.js.
2. Install the required libraries:
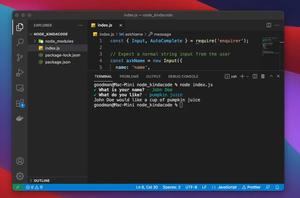
npm i got cheerio3. Add the following to your index.js:
// Kindacode.com
const cheerio = require('cheerio');
const got = (...args) => import('got').then(({default: got}) => got(...args));
// You cannot use "require" with the latest version of got
// If you're using ES Module or TypeScript, just import got like this: import got from 'got'
const extractLinks = async (url) => {
try {
// Fetching HTML
const response = await got(url);
const html = response.body;
// Using cheerio to extract <a> tags
const $ = cheerio.load(html);
const linkObjects = $('a');
// this is a mass object, not an array
// Collect the "href" and "title" of each link and add them to an array
const links = [];
linkObjects.each((index, element) => {
links.push({
text: $(element).text(), // get the text
href: $(element).attr('href'), // get the href attribute
});
});
console.log(links);
// do something else here with these links, such as writing to a file or saving them to your database
} catch (error) {
console.log(error.response.body);
}
};
// Try it
const URL = 'http://books.toscrape.com/';
extractLinks(URL);4. Run your code:
node index.jsYou should see something similar to this when looking at your console (I have reduced a lot of logs because it’s too long):
{
text: 'Libertarianism for Beginners',
href: 'catalogue/libertarianism-for-beginners_982/index.html'
},
{ text: '', href: 'catalogue/its-only-the-himalayas_981/index.html' },
{
text: "It's Only the Himalayas",
href: 'catalogue/its-only-the-himalayas_981/index.html'
},
{ text: 'next', href: 'catalogue/page-2.html' }Another Approach (Deprecated)
In this example, we’ll use request-promise instead of got. The implementation process is not much different from the example above.
Note: Because request-promise is now deprecated, you should no longer use it in new projects. I keep this section in order to provide some information for people who are still working with this library but will delete it in the future.
Installation:
npm install cheerio request-promiseCode:
const cheerio = require('cheerio');
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/Main_Page';
// I use Wikipedia just for testing purpose
rp(url).then(html => {
const $ = cheerio.load(html);
const linkObjects = $('a');
// this is a mass object, not an array
const total = linkObjects.length;
// The linkObjects has a property named "lenght"
const links = [];
// we only need the "href" and "title" of each link
for(let i = 0; i < total; i++){
links.push({
href: linkObjects[i].attribs.href,
title: linkObjects[i].attribs.title
});
}
console.log(links);
// do something else here with links
})
.catch(err => {
console.log(err);
})Conclusion
In this article, you learned how to extract all the links on a website using Node.js with the help of the got and cheerio libraries. From here, you can develop your own more complex web crawlers. Please keep in mind that many sites don’t allow you to scrape their contents.
If you’d like to explore more about modern Node.js, take a look at the following articles:
- Node.js: How to Compress a File using Gzip format
- Best Open-Source HTTP Request Libraries for Node.js
- Top best Node.js Open Source Headless CMS
- Node + TypeScript: Export Default Something based on Conditions
- Node + Mongoose + TypeScript: Defining Schemas and Models
You can also check out our Node.js category page for the latest tutorials and examples.